After the first two races I published a performance tier analysis that used sector times, top speed, qualifying pace, and race pace to cluster the eleven 2026 teams into four competitive groups. The analysis received a really sharp observation from a reader that I had not paid close attention to given the change in regulations in the new season:
“The current Formula One Regulations are predominantly dependent on Energy deployment of the battery. The 50/50 split between Internal Combustion Engine and Electric Power creates further complications in assessing peak horsepower of the different teams. The speed through the mid and high speed corners may not provide the best data as well as teams and cars are not moving at full speed as they manage battery deployment. There is further complexity with the cars having to super-clip to harvest energy at the end of each straight and losing straight line speed despite the driver being at full throttle.”
I will start by defining Super Clipping, in F1 this yearthis refers to a technical phenomenon where the cars harvest energy for their high-output hybrid batteries while the driver is still at full throttle, rather than traditional energy recovery under braking.
In the original raw SpeedST (speed-trap readings on the main straight) was used as a proxy for straight-line pace. When a car is harvesting energy it will show a lower SpeedST reading even at full driver throttle. That makes aggressive harvesters look slower on the straight than they actually are, which farther would bias the top-speed and power-sector dimensions of the DNA profile that we developed earlier.
This updated analysis adds the Japanese Grand Prix (Suzuka, Round 3) and introduces two methodological corrections to address the hybrid complication:
Harvest-lap flagging, here laps where SpeedST is more than 1.5 standard deviations below the driver’s own session mean are flagged as likely super-clip laps. Their speed readings are replaced with an imputed value (the driver’s 85th percentile speed in that session) before entering the top-speed dimension.
Power-sector down-weighting, in non-qualifying sessions, the power-sector time readings will receive a 20% reduction in the aggregation step, because Energy Recovery System harvesting has the most distorting effect in these sectors. Qualifying sessions are exempt as teams deploy maximum Energy Recovery in qualifying, so those readings represent true car pace.
Suzuka itself adds useful signal, Sector 1 normally called “the Esses” requires pure mechanical grip and minimal ERS involvement.
Caveat - three races is still a small sample
Melbourne, Shanghai and Suzuka test overlapping but different skills. The corrections below are just approximations, the profile will continue to stabilise as more circuits accumulate.
Data Collection
We extend the existing pipeline to include all standard sessions for the Japanese Grand Prix weekend.
Code
YEAR =2026# Chinese GP is a Sprint weekend; Australia and Japan are standard.RACES = {"Australian Grand Prix": ["FP1", "FP2", "FP3", "Q", "Race"],"Chinese Grand Prix": ["FP1", "SQ", "S", "Q", "Race"],"Japanese Grand Prix": ["FP1", "FP2", "FP3", "Q", "Race"],}KEEP_COLS = ["Driver", "DriverNumber", "Team", "LapNumber", "LapTime","Sector1Time", "Sector2Time", "Sector3Time","SpeedI1", "SpeedI2", "SpeedFL", "SpeedST","Compound", "TyreLife", "FreshTyre","IsPersonalBest", "Deleted", "IsAccurate",]all_laps = []for race_name, session_types in RACES.items():for stype in session_types:try: session = fastf1.get_session(YEAR, race_name, stype) session.load()exceptExceptionas e:print(f" [{race_name} | {stype}] Skipped: {e}")continue lap_data = session.lapsif lap_data isNoneorlen(lap_data) ==0:continue available = [c for c in KEEP_COLS if c in lap_data.columns] df = lap_data[available].copy() df["Year"] = YEAR df["RaceName"] = race_name df["Round"] = session.event["RoundNumber"] df["CircuitName"] = session.event["Location"] df["SessionType"] = stype all_laps.append(df)combined = pd.concat(all_laps, ignore_index=True)
Controlling for the Battery Effect
This is the core problem. Under the 2026 rules, roughly half the car’s power comes from the battery. When the battery is full, the car switches to charging mode and even with the driver flat on the throttle, the car goes slower than it normally would. That makes some laps look slow on the speed trap even though the car itself isn’t actually slow.
We deal with this in two simple steps:
We find the affected laps, if a driver’s speed-trap reading is much lower than their own typical speed in that same session, we flag it as a likely harvest lap.
We replace the bad reading, instead of throwing the lap away, we swap in that driver’s best typical speed from the session, so it no longer pulls the team’s score down unfairly.
Finding the harvest laps
Code
def flag_harvest_laps(laps_df, z_thresh=1.5):""" Flag laps where SpeedST is anomalously low — indicating ERS harvest (super-clipping) rather than a genuine slow straight-line speed. """ df = laps_df.copy()if"SpeedST"notin df.columns: df["HarvestLap"] =False df["SpeedST_ZScore"] = np.nanreturn df grp = ["Round", "Driver", "SessionType"] df["SpeedST_Mean"] = df.groupby(grp)["SpeedST"].transform("mean") df["SpeedST_Std"] = df.groupby(grp)["SpeedST"].transform("std") df["SpeedST_ZScore"] = np.where( df["SpeedST_Std"] >0, (df["SpeedST"] - df["SpeedST_Mean"]) / df["SpeedST_Std"],0.0, ) df["HarvestLap"] = df["SpeedST_ZScore"] <-z_thresh df = df.drop(columns=["SpeedST_Mean", "SpeedST_Std"])return dflaps_flagged = flag_harvest_laps(laps)
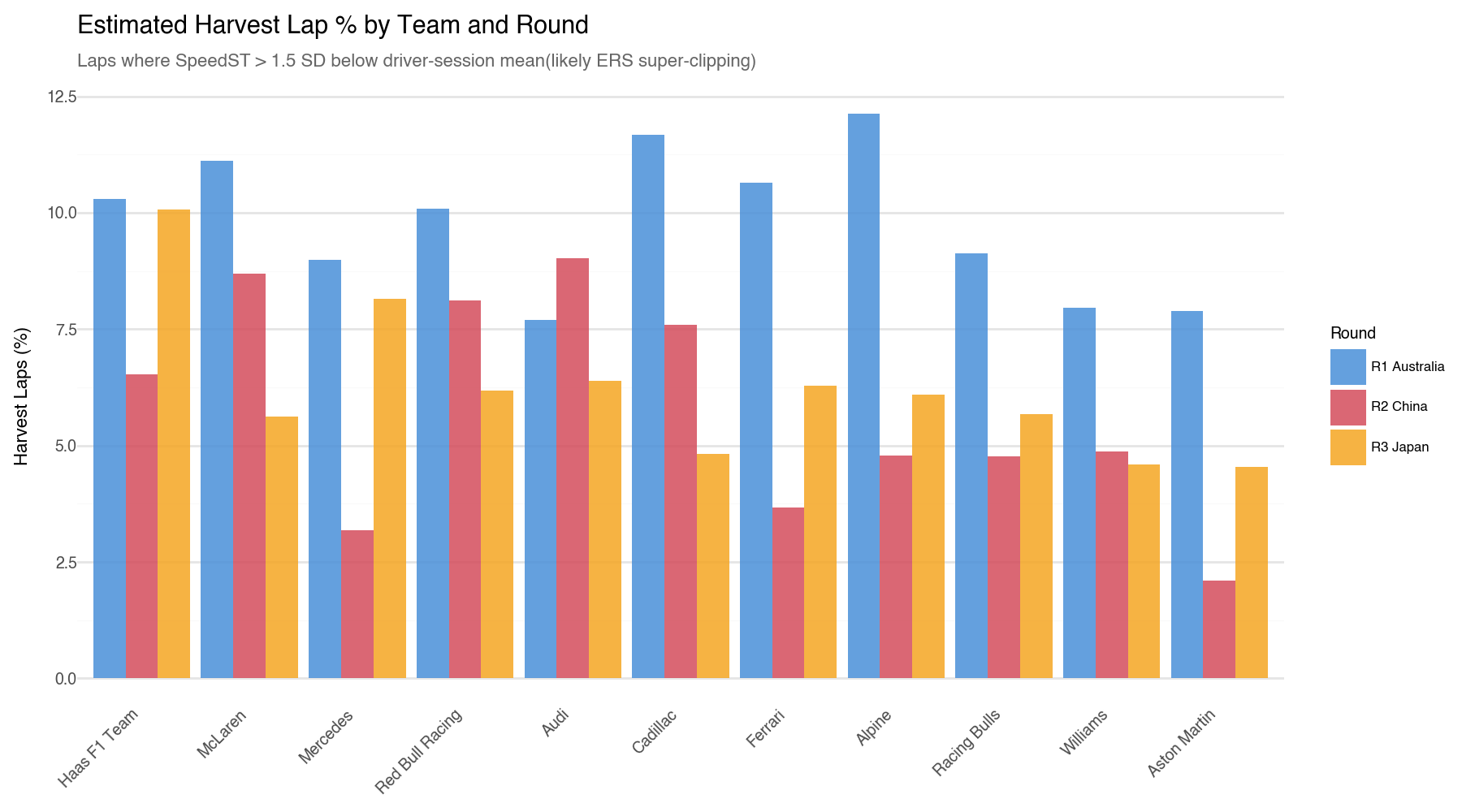
This chart reveals interesting variation across teams and circuits. Teams with higher harvest percentages are managing their battery more actively, which tells us about strategy, not pace, but it matters because without correction those laps drag down their power-sector and top-speed scores unfairly.
Replacing the bad readings
For any lap flagged as a harvest lap, we swap in the driver’s typical best speed from that session, essentially, what this car normally does on the straight when it is not charging.
Code
def hybrid_corrected_top_speed(laps_df, z_thresh=1.5):""" Compute team top speed with harvest-lap correction. Harvest laps have SpeedST imputed as the driver's p85 session speed. """ df = flag_harvest_laps(laps_df, z_thresh)if"SpeedST"notin df.columns:return pd.Series(dtype=float, name="top_speed_corrected")# p85 reference speed per driver-session p85 = ( df[~df["HarvestLap"]] .groupby(["Round", "Driver", "SessionType"])["SpeedST"] .quantile(0.85) .rename("SpeedST_p85") .reset_index() ) df = df.merge(p85, on=["Round", "Driver", "SessionType"], how="left") df["SpeedST_corrected"] = np.where( df["HarvestLap"] & df["SpeedST_p85"].notna(), df["SpeedST_p85"], df["SpeedST"], ) team_speed = df.groupby("Team")["SpeedST_corrected"].median() median_speed = team_speed.median() top_speed_cor = (team_speed / median_speed) *100-100 top_speed_cor.name ="top_speed_corrected"return top_speed_cor
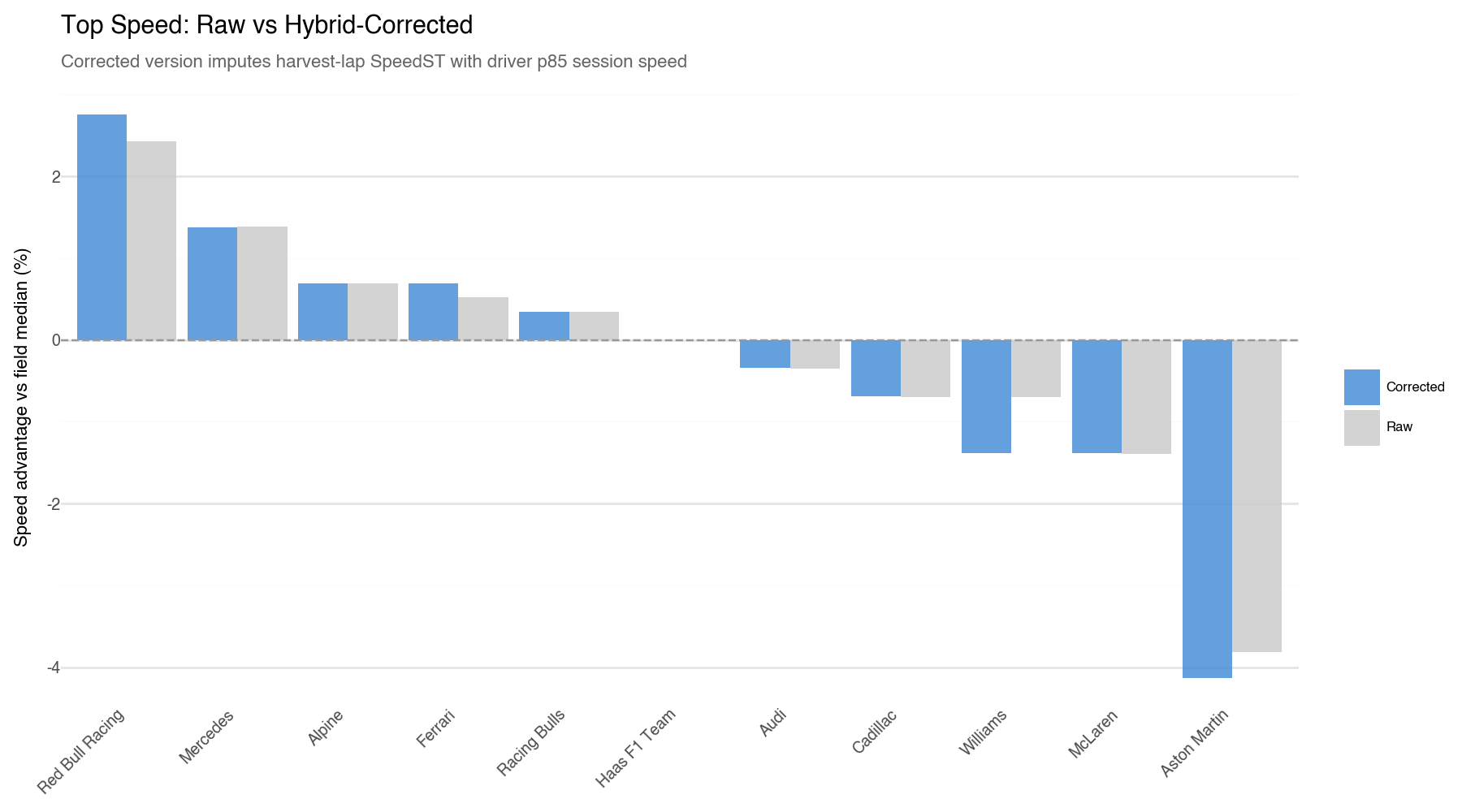
Teams that harvest most aggressively see the largest upward correction, their true straight-line pace is better than the raw data suggested. Teams that rarely harvest are largely unaffected.
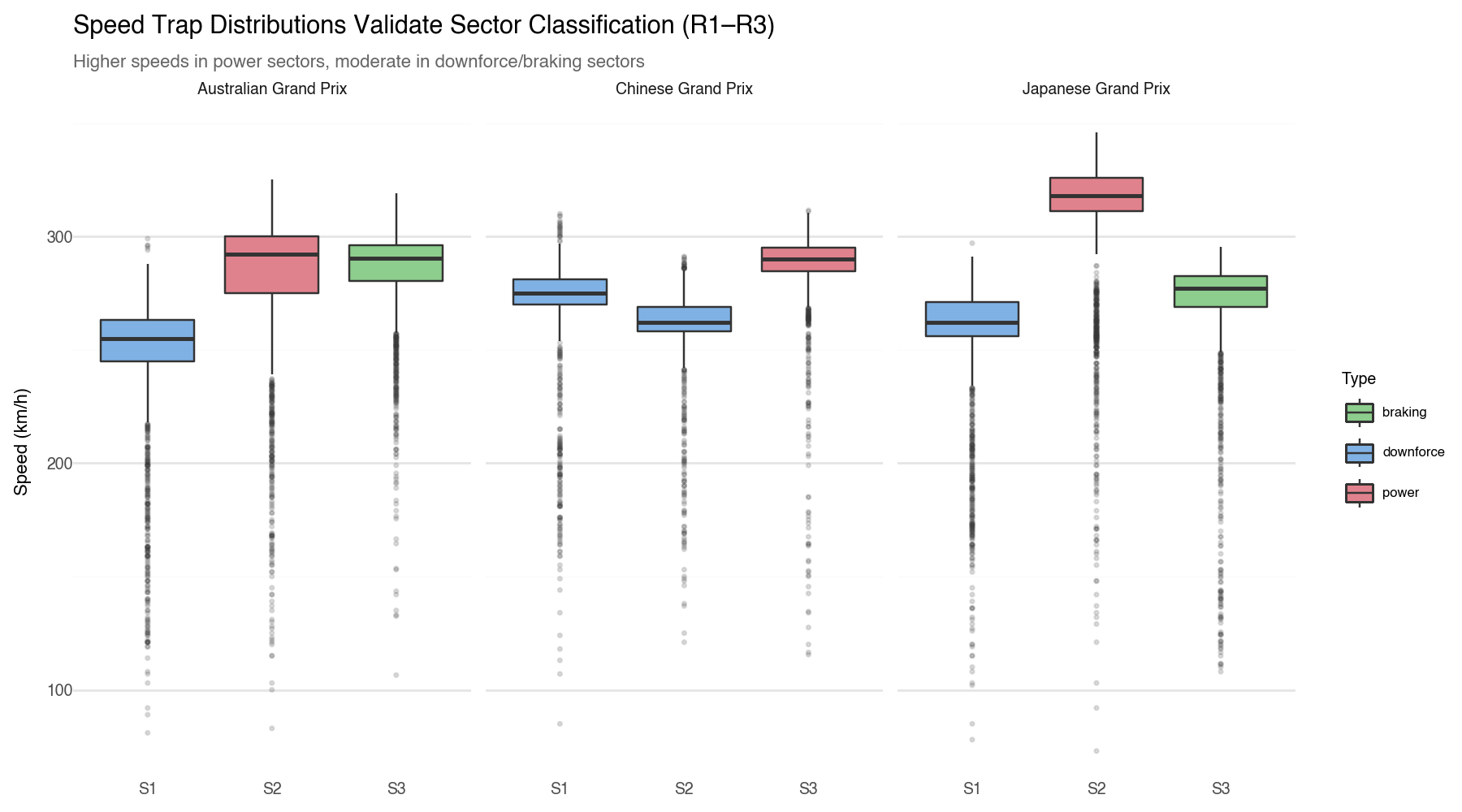
Classifying Sectors (We add Suzuka)
We now classify sectors across all three circuits.
Code
SECTOR_CLASSIFICATION = {"Melbourne": {1: "downforce", # turns 1-4: medium-speed technical corners2: "power", # high-speed sweepers + back straight3: "braking", # heavy braking into chicanes },"Shanghai": {1: "downforce", # tight/twisty turns 1-42: "downforce", # medium-high speed section (turns 5-10)3: "power", # 1.2 km back straight },"Suzuka": {1: "downforce", # Esses + Degner — pure aero/mechanical grip2: "power", # back straight + Spoon — ERS deployment zone3: "braking", # Hairpin + Casio chicane — heavy braking complex },}def get_sector_type(circuit_name, sector_num):for key, sectors in SECTOR_CLASSIFICATION.items():if key.lower() in circuit_name.lower():return sectors.get(sector_num, "mixed")return"mixed"
The normalisation approach is the same as before, we express each sector time as a percentage of the field median, but we now apply an additional discount to power-sector readings in non-qualifying sessions.
Code
SESSION_WEIGHTS = {"Q": 3.0, "Race": 2.0, "S": 2.0,"SQ": 1.5,"FP1": 1.0, "FP2": 1.0, "FP3": 1.0,}def hybrid_adjusted_weight(session_type, sector_type):""" Power-sector laps in non-qualifying sessions are down-weighted by 20 % because ERS harvest distorts straight-line speed readings in exactly those sectors. Qualifying is exempt: teams run maximum ERS deployment so the readings represent true car pace. """ base = SESSION_WEIGHTS.get(session_type, 1.0)if session_type !="Q"and sector_type =="power":return base *0.8return basedef normalize_sector_times(df, group_cols, sector_col): median = df.groupby(group_cols)[sector_col].transform("median")return (df[sector_col] / median) *100
Top-speed dimension shifted upward for teams that harvest most aggressively. If a team routinely super-clips through practice and race sessions, their raw SpeedST median was artificially reduced, the correction restores a fairer picture of their actual straight-line capability.
Power-sector scores are slightly more stable because the 0.8 × discount reduces the influence of harvest-contaminated practice sessions and lets qualifying data carry more of the difference.
The Suzuka Esses (S1) provides a harvest-free reference point. Relative performance in that sector should be treated as reliable readings in this analysis.
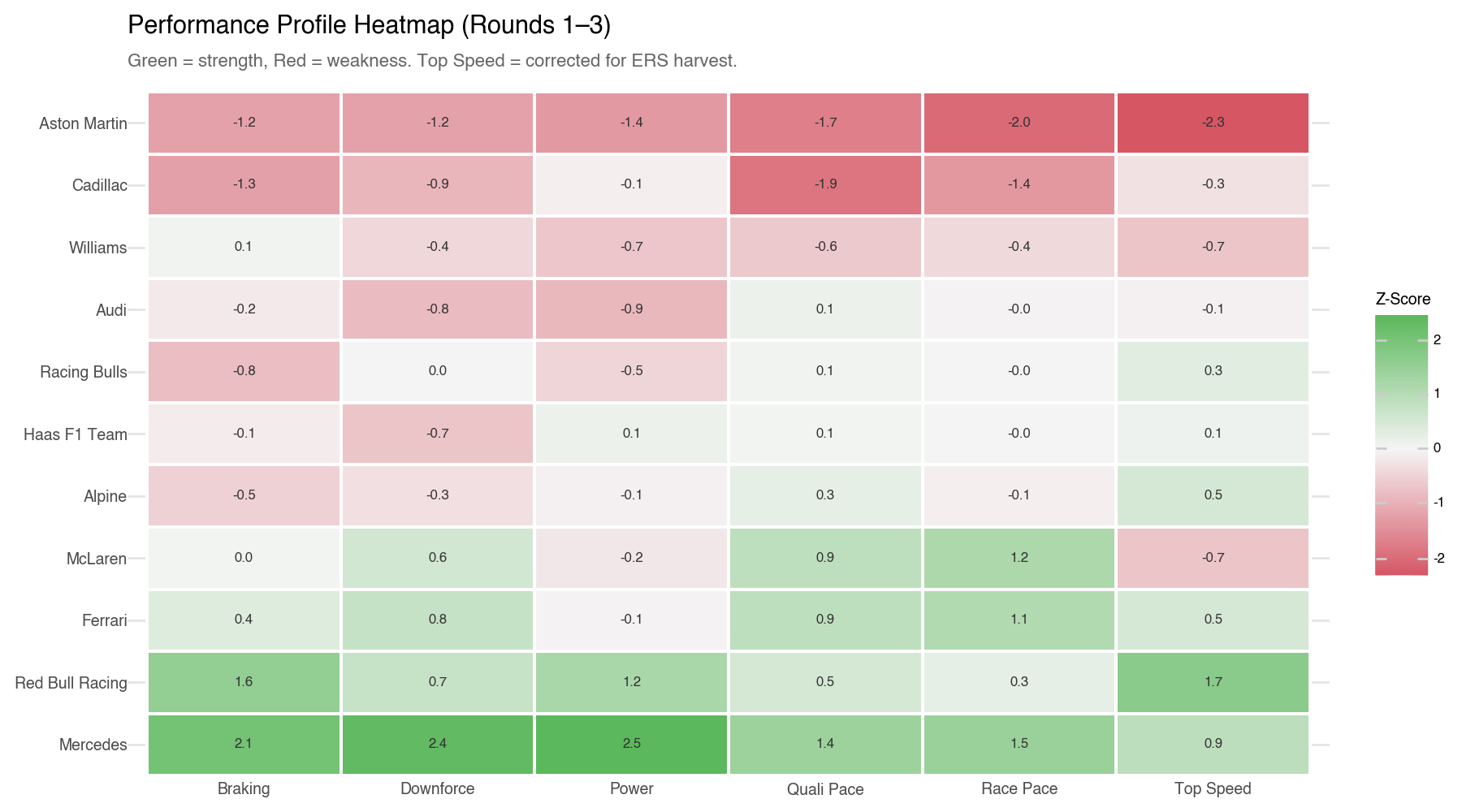
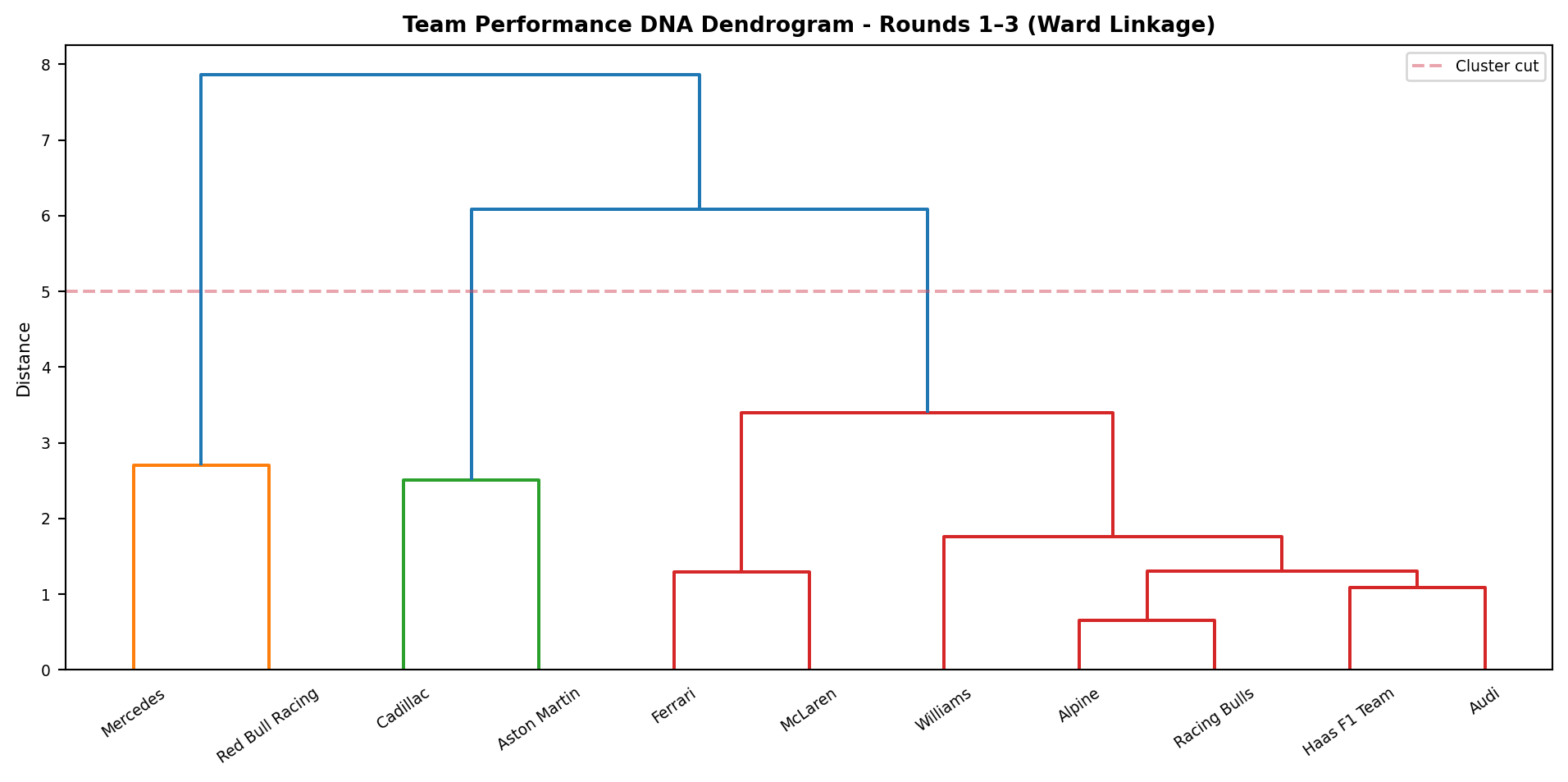
The clustering group assignments are expected to remain broadly similar to the R2 analysis, but the distances within and between groups should be more reliable now that the ERS problem has been partly addressed.
Limitations
Overall, the analysis gives useful insights but isn’t precise. The results are influenced by assumptions, limited data, and track-specific factors, so they should be seen as indicative trends rather than exact measures of car performance. As more varied race data becomes available, the conclusions will become more reliable.
Note on AI Use
AI tools were used to support coding, generate visualisations, and help debug sections of code. All decisions, interpretations, and insights presented here are the result of personal analysis.